Definition of Concurrent Processing
A user’s interaction with Oracle Applications can be broadly divided into two categories: online transactions and batch processing. The batch job processing mechanism, known as Concurrent Processing, allows application users to schedule frequently used, long running, data intensive jobs in the background while the user interacts with online data entry applications.
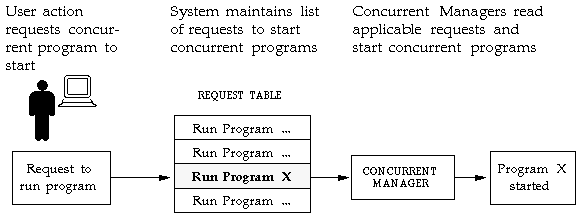
The concurrent processing function is performed by concurrent managers that act as a distributed job scheduling / execution system with sophisticated scheduling rules, including a rules engine that tracks known incompatibilities between jobs. It is common for a system to have multiple Concurrent Managers for improved throughput and conflict avoidance. When a user submits a report to be run as a concurrent request, the job enters a request queue. Concurrent Managers continuously read requests from this master queue and run requests based on the request’s schedule, priority and incompatible rules.
The end users perception of how well concurrent processing is functioning is paramount. When they submit work, they expect it to enter a queue and wait for the smallest amount of time possible before being processed quickly, efficiently and accurately by the concurrent managers. Since the end users usual interaction with the system is through its high performance online transaction processing front end, they often have high expectations of processing time in the batch processing environment. It is the task of the system administrator to manage the system to get optimum performance from the system resources in order to deliver the best possible service to the end users. Concurrent managers are central to the concurrent processing function and are one of the most important and often the most feared process within Oracle's Applications. When a system administrator can not get a concurrent manager up and all of their production or testing is backing up, this is a very stressful time.
Concurrent Processing Overview Oracle Applications Concurrent Processing is designed to act as an intermediary between Oracle Applications and the operating system. It is built on job processing facilities available on the operating system and is a technique to execute non-interactive, data-dependent programs simultaneously in the background (batch processing) thereby allowing users of Oracle Applications to submit jobs from within the application. Without the concurrent processing function, end users would have to leave the application to execute non- Oracle Forms programs such as Oracle Reports and probabilistic programs.
Concurrent processing also allows the system administrator to control the volume and type of background tasks that are processed and provides the flexibility required to set up concurrent processing to fit the needs of individual sites and their users. It allows the administrator to custom design the processing schedule to meet the business’s daily and weekly processing load by allowing control over the number of active workers at all times.
Because concurrent processing uses background processes that are not attached to any terminals, the processes continue to run even if all users sign off from the application. The advantage of this feature is to allow users of applications to submit jobs (usually CPU intensive ones) that start after hours when the load on the system is light.
Parallel concurrent processing is an extension of concurrent processing that is sometimes used to provide resilience to concurrent processing and to provide a method of load balancing for an application server by allowing CPU to be shared across multiple servers. Because of the dependence on the availability of the database server, true resilience to all types of failure is hard to achieve unless parallel concurrent processing is combined with the Oracle Parallel Server to ensure that the database is not the single point of failure.
Components of Concurrent ProcessingThere are three key components in concurrent processing. These are
• Concurrent Managers
• Concurrent Programs
• Concurrent Program Libraries
Concurrent Managers Concurrent processing consists of a number of concurrent managers which act as administrators of job processing in Oracle Applications and employ workers at the operating system to process application user requests by running concurrent programs. Each manager can run any program or be specialised to run only certain programs.
Users of Oracle Applications submit their requests to execute jobs to the concurrent managers. The concurrent managers will then take over and issue the commands necessary to execute the jobs at the operating system. Part of the concurrent manager definition is how many operating system processes (workers) it can devote to reading requests. This number is referred to as the manager's number of target processes.
Concurrent managers operate during the time and days defined by a work shift. The number of target processes is defined for each work shift, or time definition of when the manager is enabled. For each target process, a manager can start one concurrent program. For example, if a manager is defined to have five target processes, it can run up to five jobs concurrently. The maximum number of target processes for each manager is user defined and depends on available system resources.
The system administrator can define different work shifts so a manager runs a different number of processes, hence, runs a different number of concurrent programs concurrently, according to the day, time of day, and even specific dates.
When users submit a request to the concurrent managers (for example, by running a report from the Run Reports form) the request will be uniquely identified by a request ID and will be inserted into a database table (FND_CONCURRENT_REQUESTS) which acts as a queue. The concurrent managers check this queue for new requests. A concurrent manager will read from this table only those requests allowed by the manager’s specialisation rules.
You can define as many concurrent managers as you want. When you define a concurrent manager, you:
• Name, and if you wish, enter a description of your manager.
• Assign a predefined concurrent program library to your manager.
• Assign work shifts to your manager, which determines what days and times the manager will work.
• Define the maximum number of jobs (Target Processes) your manager can run concurrently per work
shift.
• Specialise your manager to read only certain kinds of requests.
From Oracle Applications Release 10.7 onwards, Oracle Applications consists of several types of concurrent managers. Key managers include the Internal Concurrent Manager (ICM), the Conflict Resolution Manager (CRM), ‘Product’ Concurrent Managers comprised of concurrent managers that let you execute application programs asynchronously and Transaction Managers that support asynchronous request processing from client machines.
The Internal Concurrent Manager (ICM) is the administrator of concurrent processing, its function is to control other managers. The ICM starts up, verifies the status of, resets, and shuts down the individual managers. With the exception of the parallel concurrent processing options for the primary node, the basic definition of the ICM may not be altered, though it is possible to set the values used for sleep time, pmon cycle and queue size when the ICM is started.
The Conflict Resolution Manager (CRM) performs the function of enforcing incompatibility rules. The basic definition of the Conflict Resolution Manager may not be altered apart from setting the CRM sleep time for each work shift and configuring parallel concurrent processing options if required. From Release 11i, another concurrent manager process called the Scheduler may also be used. The Scheduler is another single process, like the ICM and CRM that resolves complex scheduling problems
Product Concurrent Managers (e.g. Standard, Inventory, MRP, PA, and any user defined managers) are the Concurrent Managers that run your jobs. They run concurrent requests, reports and processes. The Standard Manager shipped with Oracle Applications accepts any and all requests as it has no specialisation rulesand is active all the time that the application is available. To best use the features of manager specialisation, you should exclude (disallow) jobs from the Standard Manager only when you have ensured that they can be run by a different manager. If you alter the definition of the Standard Manager and you have not defined additional managers to accept your requests, some programs may not run.
Transaction managers enable concurrent processing to support synchronous request processing. This approach was developed for the release 10 SmartClient architecture as an alternative to embedding user exits, implemented in C, in the Oracle Forms executable which would have resulted in an excessive load on the network and growth in the size of the Oracle Forms executable for every routine linked to it which, in turn, would have impacted client processing performance. In a web based configuration, from Release 11 onwards, they serve a similar purpose for the Forms Server and give a way for PL/SQL to call out to server side C packages like Vertax.
With this approach Oracle Applications can run synchronous processes on the concurrent processing server: a request from a client session to run a program makes a transaction manager run it immediately (synchronously) and then returns a status to the client program.
Transaction programs are coded as a special type of immediate concurrent program. Transaction managers are built as concurrent program libraries that contain these special immediate concurrent programs. The Internal Concurrent Manager starts these managers at run time. Rather than polling the FND_CONCURRENT_REQUESTS table, these managers wait to be signalled from the client FND_TRANSACTION package.
The execution of the requested transaction program takes place on the server, transparent to the client and with minimal time delay. At the end of program execution, the client program is notified of the outcome by a completion message and a set of return values.
The transaction manager mechanism does not establish an ongoing connection between the client and the transaction manager processes. Instead, a small pool of server side transaction manager processes service a large number of clients with real-time response.
Each transaction manager can process only the programs contained in its program library. Transaction programs and executables are defined using the Concurrent Programs form and the Concurrent Program Executable form respectively. Programs are written in C or Pro*C and are executed as immediate concurrent programs.
Each transaction manager is owned by an application and is associated with a particular data group. When a transaction request is made, the requested program’s applications and the current responsibility’s data group are used to select the transaction manager to service the request. The transaction manager uses its data group to determine how to connect to the database, connecting to the appropriate schema at startup and remaining connected until the manager process exits. Each transaction manager can only process those requests submitted from responsibilities associated with its data group. All transaction programs run by a given transaction manager process are run in the same database session.
Note: The creation of custom transaction programs is not supported.
Parallel concurrent processing and concurrent managersWith parallel concurrent processing, one or more managers can run on one or more nodes (where a node consists of one or more processors (CPUs) and it’s associated memory that is not shared with other nodes and where each node operates independently of other nodes except when sharing resources). You can run multiple managers on multiple nodes using parallel concurrent processing, and you can provide fault tolerance for concurrent managers by using secondary nodes.
The location of concurrent managers is defined during system configuration. By setting the specialisation rules of the concurrent managers on a given node, the system administrator can determine which concurrent programs will run on that node. Each node with concurrent managers may or may not be running an Oracle instance. On a node that is not running Oracle, the concurrent managers connect using SQL*Net to a node that is running Oracle.
A primary and a secondary node are assigned to each concurrent manager. Each concurrent manager is started initially on its primary node. In case of node or Oracle instance failure, the concurrent manager migrates to its secondary node, migrating back to its primary node once that node again becomes available. During the migration, the processes of a single concurrent manager may be spread across both its primary and secondary nodes.
The high fault tolerance that is required within this distributed environment to keep the Internal Concurrent Manager active is provided through Internal Monitor Processes. The sole job of an Internal Monitor process is to monitor the Internal Concurrent Manager and to restart that manager if it fails. The first Internal Monitor Process to detect the failure of the Internal Concurrent Manager restarts the Internal Concurrent Manager on its own node. The system administrator decides which nodes have an Internal Monitor Process when the system is configured. Each Internal Monitor Process may also be assigned a primary and secondary node to ensure its protection. Internal Monitor Processes, like concurrent managers, can have assigned work shifts and are activated and deactivated by the Internal Concurrent Manager.
The same form is used to define a parallel manager that is used to define a regular concurrent manager. The fields in the Parallel Concurrent Processing Details region specify the node and other parallel processing information.
Parallel concurrent processing may be used across multiple nodes in a cluster, massively parallel, or homogeneous networked environment:
• In a cluster environment, parallel concurrent processing enables full use of processing resources and increases throughput in multinode environments. Multiple computers each representing a single node share a common pool of disks. Typical cluster environments include IBM HACMP, VAX Cluster, or a cluster of Sequent servers. In this environment, a single Oracle database resides in the common disk pool while multiple instances of Oracle Parallel Server run simultaneously on multiple nodes in the cluster. Multiple concurrent managers can be distributed across the nodes in a cluster.
• In a massively parallel environment, multiple nodes are housed in a single computer with all nodes sharing access to a common pool of disks. For example, the IBM SP/2 is a massively parallel computer. In this environment, separate Oracle Parallel Server (OPS) instances run simultaneously on multiple nodes. Multiple concurrent managers can be distributed across the nodes in a massively parallel computer.
• In a homogeneous networked environment, multiple computers of the same type may be connected using a local area network (LAN) to a single database server or to a cluster of database servers. Alternatively, each node could have its own OPS instance.
Concurrent ProgramsConcurrent Programs are programs that run concurrently with other programs as background processes while you continue to work at your terminal. They may be written in Oracle Tools: PL/SQL, SQL*Loader, SQL*Plus, Pro*C and Oracle Reports or the host scripting language.
Concurrent managers can only take requests to execute concurrent programs. Once a request is picked up by a manager, the manager needs to know some information about the job in order for it to execute, for example information such as program name, execution method (Pro*C, Oracle Reports, etc.) and arguments. The information required for concurrent managers to execute the program is stored in database tables when the program is defined as a concurrent program or modified through the Application Object Library product. A concurrent program that runs in the same process as the concurrent manager that starts it is known as an immediate program, a concurrent manager initiates or spawns another operating system process for a program that is spawned.
When defining a concurrent program the application developer needs to configure how the program is invoked and run.
This process includes the following:
• Selecting an executable file to run the program.
• Choosing the execution method for the program (when defining your executable in Define Concurrent
Program Executable).
• Defining parameters for the program, if any.
• Defining printing information.
• Specifying any incompatible programs that must not run while the program runs
• Choosing whether to allow users to run this report from the Run Reports form or from within a form. If
the latter option is chosen, the form from which you want to kick-off your program needs to be modified.
If the first option is chosen, the program needs to be added to a report security group.
*****The appropriate Oracle documentation includes a full description of the steps required for this.****
Concurrent Program LibrariesA program library contains programs that can be called by the manager when concurrent managers are in operation. The workers (the OS background processes) of concurrent managers are the running instances of these program library executables.
Each concurrent manager can only run immediate concurrent programs from its own program library. In addition to this, it can run any spawned or Oracle Tool concurrent programs as spawned processes.
The system administrator may create a concurrent program library and assign it to a manager, or link in bespoke immediate program(s) to one of the existing program libraries. The advantage of linking in programs to a program library is, the assigned manager does not have to spawn another process to execute your job, hence, it will be faster to process
To create a new concurrent program library, the application developer / system administrator needs to perform various steps including:
• Creating the immediate programs
• Defining the concurrent program executable
• Defining the concurrent programs
• Defining the concurrent program library
• Assigning the program library to a manager
****The appropriate Oracle documentation includes a full description of the steps required for this. ****
Concurrent Processing Life CyclesConcurrent Processing Life Cycles To understand the internal workings of concurrent processing, it is important to be familiar with the life cycle of the concurrent managers from their startup to shutdown and the life cycle of a concurrent request in terms of the way that requests are processed by managers.
The Concurrent Manager Life CycleThe concurrent Manager Life Cycle begins when the Concurrent Manager is initiated and finished when the concurrent manager is shutdown.
Starting Concurrent Managers
The system administrator activates individual concurrent managers using the Administer Concurrent Managers form. The Internal concurrent manager must be active for an individual manager to be activated.
When the Internal concurrent manager is activated, it starts up all concurrent managers other than those that have been “deactivated” through use of the Administer Concurrent Manager screen. It can be activated from the Administer Concurrent Managers form in character mode, from the operating system or, from Release 11 onwards, via the Oracle Enterprise Manager and the Oracle Applications Manager.
When activating the ICM from the Administer Concurrent Managers form or from the operating system, the program that starts the managers is "startmgr" (located in FND_TOP/bin).
The startmgr script inherits the variables that are set in the environment where it was started and does not invoke the applications environment file. It is therefore important to ensure that the correct environment variables are set when the startmgr command is invoked. Once the concurrent manager is running, it is possible to use the FNDPRNEV concurrent program that is included in the Oracle Applications software set to check the variables that the concurrent manager is using. The variables in use are listed in the output from the program.
The startmgr script changes to the directory required to create the manager log files then calls batchmgr.
The batchmgr script starts up a shell process (the parent of all concurrent manager processes if parallel concurrent processing is not in use) then starts the Internal Concurrent Manager process FNDLIBR FND CPMGR FNDCPMBR where FNDLIBR is the command and FND, CPMGR, and FNDCPMBR are the arguments. It then creates manager log files (std.mgr and W files) in the $APPLLOG directory in $APPLCSF or $FND_TOP dependent on whether $APPLCSF is set.
On NT, the concurrent processing is implemented as a service. To start the concurrent manager, Enter the Control Panel, click on the Services icon, find the concurrent manager service, select it, and then click start. As the concurrent manager service starts, it invokes a batch file with a name in the format cm_SID.cmd in the FND_TOP/bin directory. This file sets all the required variables such as log file destinations, and values for pmon, sleep and quesiz. The Oracle Applications Installation manual for NT covers this in more detail.
Once ICM is started, it starts up the Conflict Resolution Manager (CRM), then starts other managers based on their work shift. The ICM reads from FND_CONCURRENT_QUEUES and FND_CONCURRENT_QUEUE_SIZE to get information about defined concurrent managers and their work shift. For every concurrent manager, the ICM starts as many OS processes as defined in MAX_PROCESSES field in the FND_CONCURRENT_QUEUES table. The maximum number of requests a manager can run at a time depends on its work shift. The number of processes started is the target processes.
When the concurrent managers are running, they create a program library process on the concurrent processing server(s). One FNDLIBR process appears for the ICM and each of the generic ‘Standard’ concurrent manager processes. The CRM process appears as FNDCRM, the inventory manager appears as INVLIBR and the manufacturing manager appears as MFGLIBR. On Unix, you can locate the FNDLIBR processes by running the ps – ef | grep FNDLIBR command. On NT, you can check the task manager under the process tab to see the FNDLIBR processes.
The ICM inserts a row into FND_CONCURRENT_PROCESSES for every process started at the operating system, as well as one for itself. The ICM then updates the RUNNING_PROCESSES column to reflect the actual running processes in FND_CONCURRENT_QUEUES. When all managers are running, RUNNING_PROCESSES (actual) will match MAX_PROCESSES (target). For all of the managers that are successfully started the ICM changes the CONTROL_CODE column from A:Activate to null in FND_CONCURRENT QUEUES and sets the PROCESS_STATUS_CODE in FND_CONCURRENT_PROCESSES to A:Active. Each entry in FND_CONCURRENT_PROCESSES identifies the OS process id (PID), the Oracle process id and the process status code. A shadow process is created on the database server for each concurrent manager process.
If parallel concurrent processing is in use, you can activate parallel managers by issuing an activate command against the Internal Concurrent Manager from the Administer Concurrent Managers form in character mode, invoking the startmgr command from the operating system prompt or, from Release 11 onwards, by using the Oracle Enterprise Manager and the Oracle Applications Manager. The ICM starts up on its assigned node (assuming that you operate from a node whose platform supports remote process start-up) regardless of the node from which you activate it. The Internal Concurrent Manager then starts up all the Internal Monitor Processes required to ensure that each of the nodes in use are operational and uses dcpstart and dcpbatch to start the concurrent managers on each of the remote nodes.
Shutting Down Concurrent ManagersIndividual concurrent managers can be deactivated using the Administer Concurrent Managers form.
All the concurrent managers (and internal monitor processes in a distributed environment) will be deactivated when the ICM shuts down. The ICM can be deactivated from either the Administer Concurrent Managers form (in character mode only) or from the operating system using the CONCSUB utility which returns to the operating system before or after the request completes depending upon the value of the token WAIT. Example syntax is as follows:
$CONCSUB username/password SYSADMIN ‘System Administrator’ SYSADMIN WAIT=Y CONCURRENT FND ABORT
When shutting down the ICM, you can deactivate the concurrent manager to invoke a normal shutdown or you can terminate requests and deactivate the manager to invoke a shutdown abort. If you perform a normal shutdown using deactivate, the ICM will wait for running processes to complete. It sets the max_processes column of FND_CONCURRENT_QUEUES to 0 for each manager so that they see that they should exit, then it updates FND_CONCURRENT_PROCESSES and FND_CONCURRENT_QUEUES.
If you use terminate to perform a shutdown abort, the ICM will terminate running processes then perform the same steps as before.
On NT, the concurrent manager is shutdown using the Administer Concurrent Managers form or by entering the Control Panel, clicking on the Services icon, finding the concurrent manager service, selecting it, then clicking stop. As the service closes it invokes a batch file in the FND_TOP/bin directory with a name in the format cs_SID.cmd and terminates any running requests
Once all the managers are down all concurrent OS processes are exited including shadow processes.
The PROCESS_STATUS_CODE in FND_CONCURRENT_PROCESSES is set to "S" to denote a normal shutdown or “K” to denote a shutdown abort and RUNNING_PROCESSES in FND_CONCURRENT_QUEUES is set to 0
The Concurrent Process Life Cycle Each concurrent request has a life cycle, proceeding through three, possibly four, stages or phases:
• Pending The request is waiting to be run
• Running The request is running
• Completed The request has finished
• Inactive The request cannot be run
*** Check the Oracle Documentation for detailed discription of each phase ****
How requests are processed by the managers Normal concurrent programs (programs with no constraints, QUEUE_METHOD_CODE set to ‘I’ in FND_CONCURRENT_PROGRAMS) are submitted with a status of ‘Pending Normal’ and are picked up by individual managers with no involvement from the Conflict Resolution Manager.
The number of requests that each concurrent manager process can remember when reading form the concurrent request queue is determined by the managers request cache, sometimes referred to as a buffer. The purpose of this cache is to reduce the number of hits on the concurrent requests table and reduce the probability of a manager being put to sleep because of row locks on the concurrent requests table or races with another manager to start the same request.
Each manager performs a cycle of work as follows:
1. The manager checks to see if it should shut itself down
2. If necessary, the manager shuts itself down, then exits
3. The manager reads theApplication user requests from the FND_CONCURRENT_REQUESTS table
and checks the application_id etc. to find the highest priority Pending / Normal requests that satisfy the
managers specialization rules and fills its cache as much as possible. When the manager process caches a
request, it does not lock the request, nor does it remove it from the queue. Pending requests that are
cached are still available to other managers.
4. The manager attempts to process requests in its cache serially, skipping any that have become locked,
running or completed since they were selected. For each request that it runs, the manager reads the
requests program definition and parameters (FND_CONCURRENT_PROGRAMS) and initiates the
commands necessary to execute the requested program.
5. If the manager is not able to run any requests during its cycle, it will sleep for the full amount of specified
sleep time then return to step 1 above.
6. If the manager is able to run one or more requests in the cycle then it will skip the sleep period for that
cycle and immediately return to step 1 above.
Performance Problems Users perception of performance is key. If a job is not progressing and there are no visible warnings or errors in the log files, then the immediate reaction of the end user is to assume that the application is running slow again and that performance is bad. In the eyes of the end user, poor performance is synonymous with work not being completed within the bounds of their expectations.
The task of the system administrator is to proactively manage the environment to prevent conditions arising that would create a performance degradation and monitor and resolve exceptions that could lead to problems while work is on-going.
If users perceive that performance is poor, the system administrator should work with them reactively to identify the scope of the problem in terms of its business impact, frequency, extent and precise nature. When defining the problem in this way, the system administrator should ensure that the problem definition is accurate and complete. A problem that is initially reported as a performance problem with one individual report could relate to that report alone, the Oracle Reports tool and the way that all such reports are handled, missing indexes in the database, network access to the database in a distributed environment, or poor performance of the database itself or nodes running either the database or concurrent processing. Use of the performance methodology guidelines should assist with definition of the key problem areas and identify areas for initial investigation.
In the area of concurrent processing, it is wise to take a broad view of the potential problem areas first then narrow the areas for investigation by using the evidence of the problem to dismiss those that are not causing concern.
Upon receipt of a report of poor performance within concurrent processing, the system administrator should satisfy himself that the problem is not symptomatic of a general performance problem in terms of a degradation of all work that that is either accessing the database or running on specific individual machine nodes. The first of these would indicate that the database, network and server stacks should be used collectively to ensure that database traffic is being dealt with in the optimum way. The second would indicate that the server stack should be used initially to investigate the machine performance with subsequent investigation of the load placed on the machine by the concurrent manager if the node in question was used by concurrent processing.
Once the system administrator has ensured that the problem is related to concurrent processing, it is important to identify whether all types and phases of concurrent processing are affected or whether the type of concurrent problem can be categorised by the concurrent processing phase in which the problem manifests itself. For the purposes of categorisation, four distinct phases may be identified:
• Delays may occur during the job submission phase that is after the user has submitted the request, while it is
waiting to be executed by a concurrent manager.
• Once a concurrent manager has picked up a request and started to run it, requests may experience
problems while they are ‘running’. These requests may be referred to as low performance jobs.
• If the request fails, users may experience delays in the time taken for the concurrent managers to identify
that a problem has occurred and process the error resulting in delays in termination of the request or job.
• Whether requests complete successfully or not, users may find that the amount of time that it takes to view
any associated output or log files is unreasonably long, causing problems in ‘output retrieval’.
If the system administrator finds that users are reporting problems simultaneously in all the phases that have been identified, the problem should be initially investigated in terms of the configuration that is in use. If parallel concurrent processing is in use with problems being experienced on concurrent processing nodes that are remote from the database server the network stack should initially be used to investigate the connection between the processing nodes and the database server. Subsequent investigation of the database and server stacks may also be worthwhile to investigate the database performance. If the database server is being used for concurrent processing and problems are experienced on this server, the database connection method should be checked to ensure that access to the database is direct. After that, the database and server stacks should be used for further investigation, including investigation of the load placed on the machine by the concurrent processing itself.
Identifying and Managing Delays in Job Submission If users report delays in the job submission process, it is important to first ascertain that all the concurrent managers are available and running correctly. To do this, the system administrator should ensure that the managers are running by checking that the values for target and actual processes in the Administer Concurrent Managers form are equal to each other and greater than zero or by running the afimchk.sql script that is supplied with Oracle Applications in the sql directory of the FND directory tree. From Release 11 onwards, the process monitor method used for concurrent processing must be LOCK, in this case the form which uses the lock package will be more accurate than the afimchk.sql script which uses the v$tables to find the manager status. The log files for each of the concurrent managers including the ICM and CRM should also be checked to ensure that there are no operational problems. If any of the concurrent managers have failed appropriate remedial action should be taken.
Once the system administrator has ascertained that all managers are functioning correctly, the administrator should then ensure that the concurrent processing options that have been set do not prevent the request from running.
The users request may not run if:
• The requested start is set at a future date and time.
• The request is on hold.
• The request has a lower priority than other jobs with the same start date and time.
• The concurrent program that is requested is not enabled
• No concurrent manager is defined to run the request.
• The concurrent manager defined to run the request is not available in the current work shift.
• The Concurrent Active Request Limit profile option available from release 11 onwards has been set to limit
the number of active concurrent requests.
• The Concurrent Sequential Requests profile option has been set to ensure that requests are run serially.
• A concurrent manager is already running a request that is run alone or incompatible within the same conflict
domain as the users request.
• The request is run alone and other requests are still running.
• The request is part of a report set where earlier stages have not completed successfully or incompatible
programs are delaying the request within the same conflict domain.
If the system administrator can not identify any reason why an individual job should not run and concurrent managers are running requests from other users, but have just not attempted to process the users request, there are various options available to the system administrator. These range from altering the position of individual jobs in the queue to improve the users perception of the amount of time that a request is queuing to increasing the number of manager processes that are running to increase potential concurrent processing capacity subject to the performance of the concurrent processing nodes. There are also various ways in which the system administrator can improve the throughput of existing concurrent managers.
The system administrator can reprioritise requests that are in the queue by using the form for reviewing concurrent requests. Changing the priority of the request by lowering the value of the priority assigned to it will alter the requests position in the job queue causing it to run sooner, but will not enable the job to get more resources when it runs. This type of task should therefore only be seen as a reactive measure to deal with ad hoc jobs that are not being processed by the concurrent managers as soon as individual users would like. Before proceeding with any reprioritisations, the system administrator should ensure that there is a business case for allowing the request to be escalated in the queue. If escalation is justifiable, the afcmcreq.sql script that is shipped with Oracle Applications in the FND_TOP/sql directory should be used to identify managers that would run the request and the system administrator should then ensure that they are available to run the job.
Repeated, justifiable requests from end users to alter the priorities of particular types of work should be taken as an indication that the overall workload of the concurrent processing servers should be the subject of a detailed investigation to ascertain whether an alternative strategy of concurrent manager balancing or queue specialisation should be implemented.
One disadvantage of using the mechanism of reprioritisation to appease users is that in some cases the concurrent manager may run a lower priority request before a request that has been reprioritised to start earlier. The number of requests that a concurrent manager remembers each time it reads from its queue of waiting concurrent requests is defined by the concurrent managers buffer size or cache. If a user reprioritises a request after a concurrent manager has looked at its queue, that new request must wait until the concurrent manager, or another concurrent manager, processes all the requests in its buffer. Once a concurrent manager completes all the requests in its buffer, it returns to look for the next set of waiting requests. Decreasing the buffer size assigned to the manager using the Define Concurrent Managers form and resetting the concurrent manager to ensure that the change takes effect ensures that the concurrent manager finds and starts priority requests sooner. The disadvantage of this is that the concurrent manager will spend slightly more time reading its queue instead of running requests.
If investigations suggest that delays in job submissions are related to the rate at which individual managers are able to select new work from the queue in the FND_CONCURRENT_REQUESTS table, it is tempting to try to increase the rate of throughput per concurrent manager. Dependent on the nature of the requests that are queuing in the table, the manager may be prevented from entering a sleep cycle by increasing the buffer size from the default value of 1 to ensure that it always find work in its buffer. Alternatively, the buffer size may be left at its default value and the number of seconds allocated to sleep time may be reduced thereby reducing the sleep time incurred when the manager finds on work to perform in its buffer. Both these changes could increase the throughput of the concurrent manager, at the cost of putting more workload on the concurrent processing server and increasing the likelihood of the concurrent managers locking each other out. Before implementing any changes that increase the work rate of individual managers in this way, the system administrator should be sure that the concurrent processing node is capable of performing the additional workload and that the volume and mix of the concurrent request workload warrants the change. For example, if the work rate of a concurrent manager is increased by eliminating or reducing the time that it sleeps between searching for requests in the request queue when there are no suitable requests waiting to be processed, the concurrent manager will place additional load on the server just by continuously scanning the queue in an attempt to find work.
As a rule of thumb, the default buffer size of 1 should be used so that reprioritisations can be noticed and requests run accordingly unless you have a manager that needs to service many short running (less than a minute) requests. (In release 10, the buffer size field was eliminated from the concurrent manager's definition screen by mistake however, the value may be changed in the database using the cache_size value in the FND_CONCURRENT_QUEUES table).
For a mixed workload, the sleep time for managers should never be less than the sleep value set for the CRM (or ICM if it is used) so that they do not run faster than the CRM. However, if the majority of requests on the system are submitted as ‘Pending Normal’ rather than ‘Pending Standby’, it might be best to set the managers with a smaller sleep time than the CRM.
If investigations show that there are simply not enough concurrent managers to handle the concurrent processing workload, it is possible to run more requests simultaneously by using the Define Concurrent Manager form to add more concurrent managers or increase the number of requests that your existing concurrent managers can run. These changes take effect after you reset the concurrent managers. Although increasing these two options can decrease the time that you wait for pending requests to start, they can also increase your system workload thereby increasing the amount of time each request takes to complete and degrading overall performance. Such amendments should be made in a controlled fashion after fully investigating the impact on the machine and considering aspects of concurrent manager balancing and queue specialisation that are discussed later.
Identifying, Managing and Resolving Low Performance Jobs If users report poor performance in requests that seem to be running, it is important to first ensure that there are no errors in the log files and that requests have not been wrongly left in a ‘Running’ status by a dead (abnormally exited) manager process that has not (yet) been detected by the ICM. When the ICM is operating correctly, it checks for the heartbeat of active manager processes during its pmon cycle and looks for abnormally terminated concurrent managers. If the pmon cycle is set too high, there may be a delay in finding dead manager processes. If the ICM fails, requests may be wrongly left in a ‘Running’ status after the manager has failed. Check that the ICM is active running by reviewing the Administer Concurrent Managers form and checking that the actual and target processes are both set to 1 or by running the afimchk.sql script in the FND_TOP/sql directory. Also ensure that the pmon cycle time is set at a reasonable level to detect problems in a timely fashion.
A request may also be suspended in a running state if:
• The request requires a row or table that is locked by another user
• The temp directory is full
• The request has become a runaway request where Oracle or Unix has lost track of the request.
If the request genuinely seems to be running more slowly than would normally be expected, check the parameters that users entered to ensure that they are not inadvertently running open-ended reports that provide more information than they intend to retrieve. Review any timings in the request log file to see if they seem reasonable.
If the request log file indicates that there are some parts of the request that seem to run particularly slowly, try to identify problematic SQL using trace to reproduce the problem if possible. If you can identify individual statements that are causing problems, use the SQL Tuning stack to investigate them further.
If the whole request seems to be slow, investigate whether this is part of a general trend. Determine whether there are other requests that are performing badly and identify any characteristics that they have in common.
Consider whether performance problems are timebound or related to individual work shifts. If there are peaks and troughs in performance throughout the working day, review the workload on the machines at key times. Review the concurrent processing workload and any other work that the machine performs at key times. Investigate the possibility of balancing online and concurrent processing workload through techniques of concurrent manager balancing and queue specialisation described in detail below.
If the problem seems to be associated with requests that are being processed through the transaction managers, use the network stack to investigate the network between the forms server and the concurrent processing server. Ensure that network traffic between these two points is being dealt with in the optimum way.
If the problem is restricted to individual users or responsibilities and you are using Oracle Applications Release 11i, check your use of the cost based optimiser to ensure that you are following best practices.
If the problem seems related to individual tools or standard reports, check for known performance problems through Oracle Support Services. Report any performance problems with standard requests to Oracle Support Services and investigate problems with custom code in-house.
Identifying and Managing Delays in Job Termination As with problems involving poor performing requests, it is important to ensure that the ICM is operational to resolve any issues with requests that have failed and need to terminate. On receiving reports of requests taking a long time to terminate, the system administrator should ensure that the ICM is active running and that the pmon cycle time is set at a reasonable level to detect problems in a timely fashion.
Once the concurrent job has indicated an intention to rollback, the database server takes over and controls the rollback. Performance problems in this area will therefore be related to the rollback activity itself in terms of rollback configuration or general database performance. Performance of the network is not an issue as the rollback activity is contained on the database server. There is therefore no need to investigate the nodes that are running the request or network performance.
Identifying and Resolving Delays in Output RetrievalThe System Administrator and Oracle Alert Manager responsibilities have a 'privileged' version of the View Concurrent Requests form or window that allows them to view the status of, and log files for, all concurrent requests, including those that have completed unsuccessfully, and to perform various administrative tasks on concurrent requests. Other responsibilities can manage and view their own report output online, but they cannot view report output from other users' requests.
You display the Requests window by choosing View Requests from the Help menu. This window lists all your concurrent requests. Pressing the Diagnostics button displays the Request Diagnostics window, which presents summary information about an individual request in a Cause and Action format.
If you are working in a SmartClient environment and you saved the output file for your concurrent request, you can view your completed report online, reprint it and copy it to the client machine. From release 10.7 onwards, the recommended method is to use the Report Review Agent.
When you generate a report, the report output file is saved to the server’s file system. You can output to a printer directly attached to the server and avoid any network traffic. Or, you can take advantage of Report Review Agent, the Remote Procedure Call - based online report viewer, which takes advantage of RPC functionality which is available with Oracle7 Server 7.3.2 onwards and is designed to be lighter on network traffic.
The RPC-based viewer supports both character and Postscript formatted reports. You issue a request to run a concurrent request on the 10SC client. This request is picked up by the standard concurrent processing facility and run. The request writes a log file and, where appropriate, a report file to the application server's disk. When you invoke the online report viewer, Oracle Applications makes a remote procedure call (RPC) to initiate a report review agent on the server. The report review agent on the server checks the report to determine whether it is a character or a Postscript report.
If it is a character report, the report review agent opens the report output or log file you have asked to see and transmits the first page across the network to the client-side viewer. You can then request the next, first or last page, or any page number you want to view, and the report review agent will locate and transmit only that page across the network. You can request to have the entire file downloaded to your PC client, subject to size restrictions set by your system administrator through a profile option, saving it to a file name of your choosing.
If the report is Postscript, the review agent downloads the entire file to your PC and invokes whatever editor is defined in the postscript editor profile option.
Once a report is downloaded to your PC client, you can choose to view it with a desktop tool such as Word or Excel, or to print it to a local printer.
It is possible to set up custom editors to specify a desktop product such as Word or Excel as your default viewer by setting some user profile options, but this causes an automatic download of the entire report to a temporary directory on your PC before you can view it with your desktop product and thus produces more network traffic than viewing a page at a time with the RPC-based viewer.
All file transfers are subject to restrictions imposed by the System Administrator on file transfer size.
This 10SC report viewing technology enforces the same security as the standard Release 10 report viewer. You can view only those reports that you submitted, or, if your system administrator allows, you can view all the reports submitted by users sharing your responsibility.
The appropriate Oracle documentation includes a full description of the tasks that need to be performed in order to use the Report Review Agent. Primarily, these are:
1. Install the Oracle Network Manager so that you can generate the files needed by the Report Review
Agent.
2. Configure the Report Review Agent using the Oracle Network Manager, then copy the configuration files
that Oracle Network Manager generates to the client and to the server.
3. When using a custom editor to view concurrent output or log file, the Report Review Agent will make a
temporary copy of the file on the client. Set the File Server:Delete Temporary Files profile option to Yes
to automatically delete files when the user exits Oracle Applications.
4. Set the File Server:Maximum Transfer Size profile option to specify in bytes the maximum allowable size
of files transferred by the Report Review Agent, including those downloaded by a user with the Copy File
menu option in the Oracle Applications Report File Viewer and those ‘temporary’ files that are
automatically downloaded by custom editors. Null means no file size limit.
5. When the Report Review Agent is configured, the SQL*Net listener will spawn a process that serves files
to the client. The operating system account used to start the TNS listener, usually the Oracle account,
must have file permissions to read the log and report output files for all products and to read and execute
the FNDFS executable in the FND product bin directory.
In an internet computing environment, the forms servers communicate directly with the concurrent processing servers when reports are retrieved for on-line viewing. In Release 11, this is done by using Net8 to issue a Remote Procedure Call to the concurrent processing server. The concurrent processing server runs a Net8 Listener which responds to the request by invoking an Oracle Applications executable then returning the results via Net8. Network Latency between the concurrent processing server and the forms server may result in Applications data being returned more slowly to Applications users.
To configure and set up the Web Report Review Agent, the Report Review Agent should be set up and configured as for the Smart Client environment as outlined above substituting the Forms Server for the PC client. Once this is done, it should be possible to view files using the Applications Report Viewer (appsviewer). When using certain features, such as context sensitive help and Web Report Review, the Appletviewer launches a browser to view files. To configure this, the initial HTML file should be edited to add the name of the browser that you wish to use to view help, attachments and reports and each client path should include the directory that contains the browser. Details of other variables that need to be set are provided in configuration guides for the Web Review Agent.
Whether working in a SmartClient or internet computing environment, it is good practice to limit the size of the maximum allowable size of files transferred by the Report Review Agent. This includes files downloaded by the user with the 'Copy File' menu option in the Oracle Applications ReportFile Viewer and 'temporary' files that are automatically downloaded by custom editors. Set the RRA:Maximum Transfer Size to specify the maximum file transfer size in bytes. This ensures that the network is not flooded with data and ensures that it is available for all types of transactions with no major degradation resulting from output retrieval. Apart from maintaining the integrity of the network, there is little else that can be done to improve the rate at which output is retrieved or viewed.
In a distributed environment, you can review log and output files from any node, regardless of which node the concurrent process runs on. You do not need to log onto a node to view the log and output files from requests run on that node. The concurrent log and output files from requests that run on any node are accessible online from any other node. This capability relies on set-up steps taken at install time. For more information, refer to the installation documentation for your platform.
Improving the Performance of Concurrent Processing The key to good performance and smooth system administration is to proactively resolve problems before they turn into crises. As an on-going practice, it is important to ensure that you obtain best results from the machine and processing resources that you have.
• Educate users and encourage them to schedule long-running, non-critical requests outside core hours.
• Monitor parameters that users enter to ensure that they are not inadvertently running open-ended reports
that provide more information than they intended to see.
• Monitor for locks on tables to ensure that users are not locking each other out of tables for an extended
period of time.
• Watch for runaway requests where a requests take a long time to run, showing increasing CPU clock time
with a process id of 1 on Unix with no other Unix processes referencing them. These are ones where
Oracle or Unix has lost track of the request. If this is the case, the processes may not be cleaned up
automatically by Oracle. On Unix, the kill command may be used to terminate them. Runaway processes
from any other source should also be monitored and dealt with.
• Monitor for failures of the ICM or CRM that could result in delays in processing jobs with incompatibilities
or delays in detecting other manager problems that would result in a queue backlog building up.
• Report performance problems with standard reports to Oracle Support Services, investigate problems with
custom reports in-house.
In the longer term, you can really only achieve better processing throughput and performance by adjusting concurrent manager assignments and request scheduling. Use historical information in AOL tables to gather information, subject to data purge policies of the system administrator.
After analysis of concurrent processing workload, it may be appropriate to customise the available concurrent managers to optimise the use of concurrent processing by balancing the flow of processing. Work shifts and specialisation rules can be used to achieve this by customising existing manager definitions or adding new ones.
Long running, expensive jobs may be isolated and forced to run serially in their own concurrent managers, possibly even outside regular office hours to avoid too much of a drain for other types of work in a normal high level transaction processing environment.
Jobs with a similar profile may be grouped together and processed by the same concurrent manager to enable each manager to be defined in a custom way to increase efficiency. For example, running all unconstrained jobs through a manager with a low sleep value reduces the likelihood that it will ever be unable to run work and thereby causes it to run continuously without invoking its sleep parameter.
Concurrent Manager BalancingDetermine which concurrent manager and program combinations are potential bottlenecks by identifying which concurrent managers run which programs. Use data in the AOL tables to identify requests that would be suitable candidates for rescheduling to distribute load more evenly.
Identify time periods with the greatest wait times and examine requests that were run and that were waiting during this time. Conversely, identify time periods when concurrent managers had excess capacity by comparing jobs that were run by each concurrent manager against its total capacity to determine capacity utilisation.
To reduce wait time and balance queue usage, consider rescheduling a program to run when the concurrent managers have excess capacity. Alternatively consider designating certain concurrent managers to process either short or long running programs to help mitigate queue backup.
If all queues are running at or near maximum capacity, it may be necessary to add more queues. You can define as many concurrent managers as analysis of your workload requires and as the power of your server allows. However, you should exercise caution to ensure that the CPU of the machine is not overloaded through the use of excessive manger definitions or processes assigned to each manager definition.
If all system resources are also fully utilised, it may be necessary to add additional hardware to support processing demands or consider using (or extending) a parallel concurrent processing environment.
Queue SpecialisationMeasure elapsed run time of requests to identify jobs that consistently take a long time to run and those that consistently complete in a short time. Compare the running time of fast requests to the time that they regularly spend queuing. Ensure that your findings are consistent over a period of time by querying the fastest and slowest times that each request took to run the longest and shortest times that they waited and the total number of times that each job was executed. Use the information gathered to decide how to assign programs to queues and choose candidates for further tuning.
Designating a concurrent manager to process consistently short running jobs can help prevent such jobs getting stuck behind long running jobs in the queue. If many short running, but long waiting requests are identified, consider creating a concurrent manager that specialises in short running requests. This may increase the throughput of these requests.
Look at long running requests to determine if any of these requests should be associated with a queue that will handle long running jobs. Consider defining a separate concurrent manager to process consistently long-running, non-business critical requests outside core business hours to segregate jobs that are prone to cause bottlenecks in processing away from other business functions.
Identify business critical jobs with the users to ensure that these are treated as special cases irrespective of their running time. Allow any other programs that vary in running time to run in the default Standard queue unless there is some other business reason why they should be handled differently from other core business processing.
Defining and Tuning Individual Concurrent ManagersVarious options are available for defining and tuning each manager.
Internal Concurrent Manager There are three parameters that affect the performance of the ICM which may be set during startup of the ICM. These parameters are:
Sleep time - the number of seconds that the internal concurrent manager waits between times it looks for new concurrent requests if the profile option Use ICM is set to yes. Use default setting of 60 seconds.
Pmon cycle - the number of sleep cycles the ICM waits between time it checks for failed concurrent managers. This can be set lower than the default setting of 20 sleep cycles since the resources consumed by PMON do not justify such a large delay now that the CRM is used in place of the ICM to process constraints.
Queue size - the number of PMON cycles that the ICM waits between times it checks for new or disabled concurrent managers. Use the default setting of 1 pmon cycle.
Note that amendments may be made to the values for pmon and queue size on the fly by updating the settings and using the ‘Verify’ option on the Administer Concurrent Managers form to reset the values used by the ICM.
Conflict Resolution ManagerSleep time is the only parameter that may be reconfigured for the conflict resolution manager. It is wisest to set the CRM sleep time for a given shift in the Define Concurrent Manager form rather than to hard code values. Use the default setting of 60 seconds.
Product ManagersSleep time - the number of seconds that the manager waits between checking the list of pending concurrent requests. By default, the sleep time for the product managers is set to 60 seconds but it may be modified in the 'Work Shifts' zone of the 'Define Concurrent Manager' screen. \Nav Con Man Def. As a rule of thumb the sleep time for managers should never be less than 60 seconds with a mixed workload so that they do not run faster than the Conflict Resolution Manager. However, if the majority of requests on your system are submitted as ‘Pending Normal’ rather than ‘Pending Standby’ it might be best to set the managers with a smaller sleep time than the CRM
Buffer (Cache) Size - the number of concurrent requests that the manager picks up from the FND_CONCURRENT_REQUST table when the manager wakes up. For customer defined managers the Cache Size is either blank or set to 0 which is interpreted as a value of 1 when the manager is started. Use the default buffer size of 1 so that reprioritisations can be noticed and run accordingly unless you have a manager that needs to service many short running (less than a minute) requests. If this is the case, consider setting the buffer size to equal at least twice the number of target processes. For example, if the manager has three target processes it could run three jobs. But if it only picks up one job every 60 seconds then you are losing valuable processing time. If it picks up six jobs then the managers will continuously be processing. If reprioritisations are not important to your business, this rule may also be applied to other processing to increase the throughput of the concurrent managers by attempting to avoid any sleep time.
Target processes – Define concurrent managers with a minimum of two target processes to reduce the possibility that work will stack up behind one long-running job, unless the queue has been specifically configured to run long-running tasks sequentially to reduce overall load on the system. Reasonable rule of thumb is to limit the number of concurrent requests that can run during core business hours to a maximum of 20.
Work shifts – Define work shifts that map on to business events, for example, during core business hours, minimise the number of concurrent requests in favour of on-line users, when on-line users go home define out of hours work shifts that give concurrent requests priority over other processing. Consider placing a different emphasis on job mix at weekends or during any month end processing to complement the work that the users are trying to complete.
If you use online backups, there are no additional restrictions on how you should manage your workshifts. However, if you use cold backups, you should try to define workshifts that complement your backup recovery strategy. When you shut the database down for cold backups, you will need to manage workshifts leading up to the time when the database is brought down and consider how to re-process any terminated requests after the backup, before core business hours commence.
It is possible to command the concurrent manager to wait for all running work to be processed before shutting itself down. In this scenario, it is not possible to predict when or whether the concurrent manager will shutdown if there are long-running tasks that are running or runaway processes that are still attached to the concurrent manager that prevent it from shutting down. An alternative method is to command the concurrent manager to shutdown immediately without waiting for requests to finish to ensure that backups are started and completed within the available database down time. Since the ICM only restarts requests in cases of complete system failure (either node or database failure), any aborted requests will need to be identified, fixed and reran. In this latter scenario, it is wise to try to eliminate long-running jobs from the work shifts running immediately before the backups to reduce the impact on the system of reprocessing terminated work when the concurrent managers are started up again after the backups.
######################################################
Source:-
http://appsdbaexperts.blogspot.in/2010/09/concurrent-processing-tuning.html